WebServices to Microservices
When you are talking about microservices, chances are your existing application is built as web services. These days a lot of people and vendors are calling these web services as microservices and it is not right.
The following diagram shows the difference between web service and microservices.
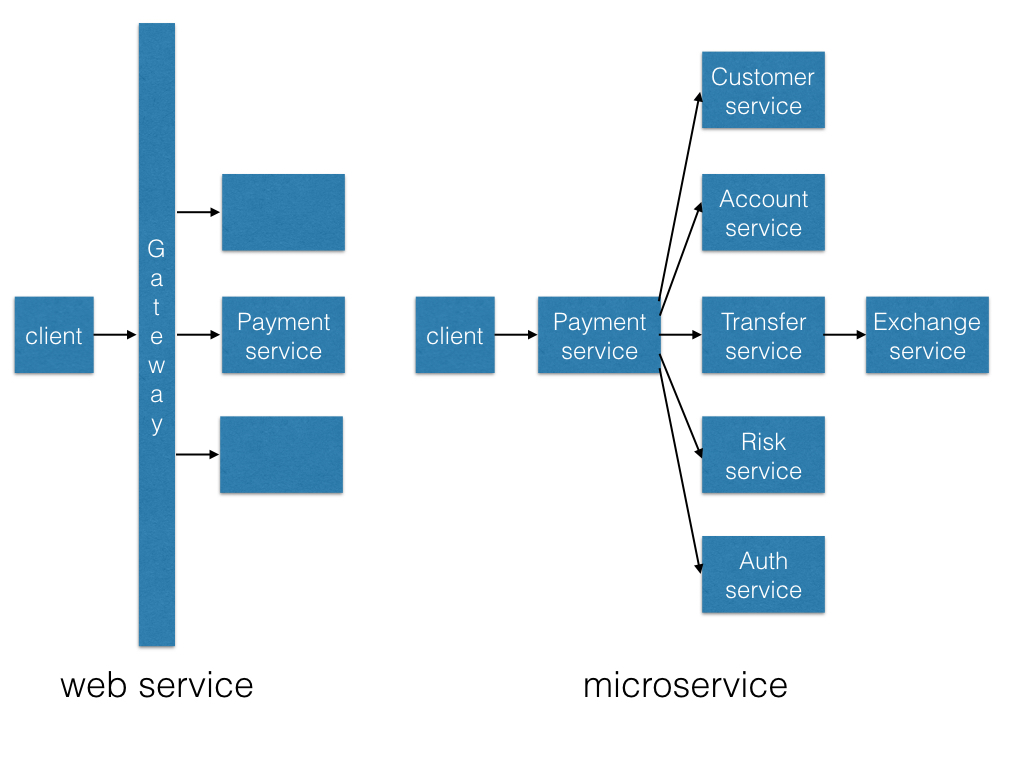
As you can see, the traditional web servers are flattened behind an API gateway and they are normally built on top of Java EE platform with JAXRS 1.1 or 2.0
In essence, each web service is still a big monolithic Java EE application and does everything in a war or ear file. Although they expose RESTful API but they are not microservices.
On the right side, the same payment API is broken up to microservices and the payment API in the picture acts as a facade API which has a static ip address and can be accessed from F5 (or another reverse proxy and load balancer) directly. Unlike the web service which does everything in the same application, the microservice payment API will call customer service to get customer info, get account service to check the balance, call risk service to make sure there is no money laundry risk, verify if the customer has the right to do the transaction with auth service. Then, it will call the transfer service to move funds from one account to another. If the two accounts are in different currencies, then the currency exchange service will be called to convert the currency from one to another.
As you can see, the network communication in the microservices diagram is more significant than web service. This is why the traditional commercial API gateway is not suitable in this architecture as it will become a bottleneck and a single point of failure. Most gateway products on the market today are Java EE based monolithic applications that are against distributed principles of microservices architecture.
Microservices architecture evolves from monolithic application architecture naturally as a monolith grows to a certain stage that becomes not maintainable and not scalable. Imagine that you have a big application and only one developer knows it inside out and every time one line of code is changed ten other places are broken. This makes every release risky, with several months of testing cycles to ensure that nothing is broken. In order to meet the demand from business growth, the application can only be scaled horizontally and it is all or nothing. You cannot scale an individual service which is facing volume spikes during the month end or year end.
From another perspective, it is natural for human beings to break up complex things into simpler and smaller pieces to tackle them. This is not just limited to computer software but in every field. According to brain science, most people can only remember 7 to 9 things in the short term and focus on them at a particular moment. Can you imagine a big application with thousands moving pieces? A good developer/programmer must have very good short term memory so that their brain can wire many things together.
In the history of software programming, developers broke things up all the time. If you have ever worked on assembly in early years, you know it is a big monolithic app with one entry point and so many goto statements. Some smart developers tried to extract common and repeatable code into the function so that it can be called from different places.
A monolithic application is just like a Java class with only one main method with thousands lines of code. In order to make it easy to read and maintain, some of the duplicated lines of code should be extracted into other methods in the same class or some other classes. This makes developers’ lives easier because when you work, you are dealing with only one class or one method at a time. The only problem with this kind of breaking up is classes and methods are tightly coupled and there are a lot of assumptions in these class and method calls. This is why you change one method to fix an issue for one caller. Other callers are broken as they have different assumptions although the signature of the method has never been changed. Another issue with this kind of breaking up is you have to package your changed method/class with others as one deployment unit to deploy them together to production and the entire deployment process is very risky.
Microservices just go to the next step, instead of separate methods or classes calling in-process. We make these reusable pieces as inter-process services invoked through HTTP. The benefit is you can update/replace individual service independently without impacting the entire application. As these services are very small, they are easier to be implemented and maintained by developers.
Unlike class or method calls, calling microservices over the network is very slow. So it is unwise to break an application to thousands of pieces, as every request will have to go through 50 to 100 network hops to get it done. The network latency will kill the performance no matter how you scale your services.
Whenever possible, the calls to other services should be done in parallel so that the slowest service will decide the response time. If you call multiple services in serial, then the sum of these services will be your response time.
Given the above nature of microservices, a low latency HTTP server is very important so that it won’t add too much overhead to each service to service call. Also, as service calls are over the network, there are a lot of things that need to be handled like security, logging, metrics, auditing, service registry/discovery etc. This is why you need a framework to build microservices so that developers can only focus on the business logic of the service without worrying about cross-cutting concerns. The light-4j framework is designed just for that.