Scalability and Performance
One of the benefits of utilizing microservices architecture is to make sure your application scales easily. When we talk about scalability, one of the best books is The Art of Scalability
It introduces the scale cube as follows:
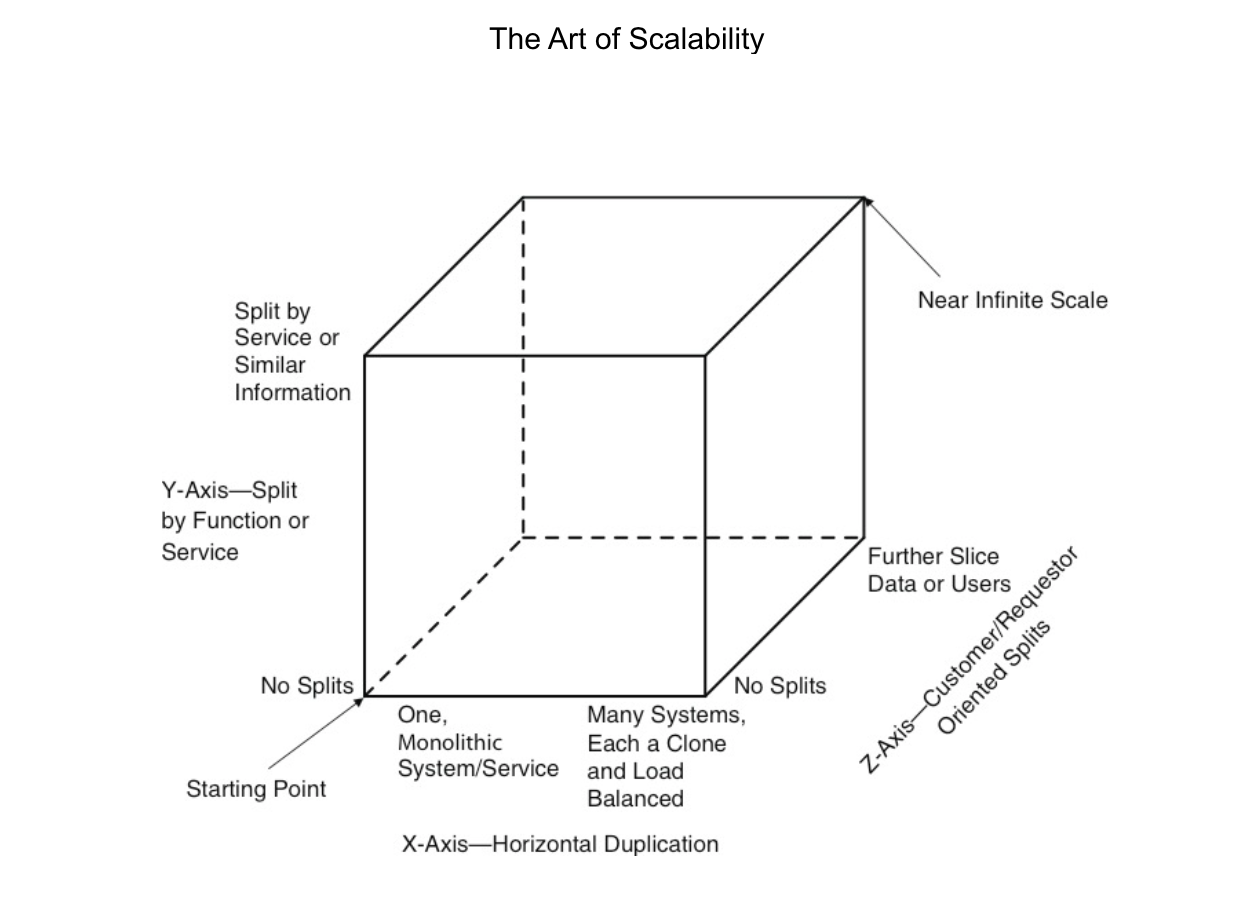
The Scale Cube consists of an X, Y and Z axes – each addressing a different approach to scale a service. The lowest left point of the cube (coordinates X=0, Y=0 and Z=0) represents the worst case monolithic service or product identified above: a product wherein all functions exist within a single code base on a single server making use of that server’s finite resources of memory, cpu speed, network ports, mass storage, etc.
In this model, scaling an application by running clones behind a load balancer is known as X-axis scaling. The other two kinds of scaling are Y-axis scaling and Z-axis scaling. The microservice architecture is an application of Y-axis scaling but let’s also look at X-axis and Z-axis scaling.
X-axis scaling
X-axis scaling consists of running multiple copies of an application behind a load balancer. If there are N copies then each copy handles 1/N of the load. This is a simple, commonly used approach of scaling an application.
One drawback of this approach is that because each copy potentially accesses all of the data, caches require more memory to be effective. Another problem with this approach is that it does not tackle the problems of increasing development and application complexity.
Y-axis scaling
Unlike X-axis and Z-axis, which consist of running multiple, identical copies of the application, Y-axis axis scaling splits the application into multiple, different services. Each service is responsible for one or more closely related functions. There are a couple of different ways of decomposing the application into services. One approach is to use verb-based decomposition and define services that implement a single use case such as checkout. The other option is to decompose the application by noun and create services responsible for all operations related to a particular entity such as customer management. An application might use a combination of verb-based and noun-based decomposition.
Z-axis scaling
When using Z-axis scaling each server runs an identical copy of the code. In this respect, it’s similar to X-axis scaling. The big difference is that each server is responsible for only a subset of the data. Some components of the system are responsible for routing each request to the appropriate server. One commonly used routing criteria is an attribute of the request such as the primary key of the entity being accessed. Another common routing criteria is the customer type. For example, an application might provide paying customers with a higher SLA than free customers by routing their requests to a different set of servers with more capacity.
Z-axis splits are commonly used to scale databases. Data is partitioned (a.k.a. sharded) across a set of servers based on an attribute of each record. In this example, the primary key of the RESTAURANT table is used to partition the rows between two different database servers. Note that X-axis cloning might be applied to each partition by deploying one or more servers as replicas/slaves. Z-axis scaling can also be applied to applications. In this example, the search service consists of a number of partitions. A router sends each content item to the appropriate partition, where it is indexed and stored. A query aggregator sends each query to all of the partitions, and combines the results from each of them.
Z-axis scaling has a number of benefits.
Each server only deals with a subset of the data. This improves cache utilization and reduces memory usage and I/O traffic. It also improves transaction scalability since requests are typically distributed across multiple servers. Also, Z-axis scaling improves fault isolation since a failure only makes part of the data in accessible.
Z-axis scaling has some drawbacks.
One of the benefits of utilizing microservices architecture is to make sure your application scales easily. When we talk about scalability, one of the best books is The Art of Scalability.